Standardsoftware vs. IndividualsoftwareIn den letzten Jahren wird immer häufiger die Frage gestellt, was ist besser Standardsoftware oder eine Individuallösung? Die Beurteilung ist selbst für Experten schwierig geworden. Diese Abhandlung ist der Versuch mit naturwissenschaftlichen Methoden und Betrachtung der Geschichte der Informatik eine Antwort zu finden.Dazu zunächst folgende Zahlenreihe 
der Aufbau dieser Zahlenreihe ist leicht zu verstehen. Zu einer am Anfang der Zahlenreihe stehenden 5 wird eine 2 addiert zu der resultierenden Zahl wird wieder eine 2 addiert usw. Es ist sofort verständlich, dass eine derartige Zahlenreihe auch mit Hilfe einer Formel ausgedrückt werden kann. 
Jedes Element der obigen Zahlenreihe, lässt sich mit dieser Formel errechnen. Abstrahiert man diesen Umstand ein wenig und fasst die Zahlen in der obigen Zahlenreihe als Ereignisse auf, wird klar, dass man mit Hilfe der Formel Ereignisse voraussagen oder Ereignisse in der Vergangenheit nachvollziehen kann. Diesen Vorgang nennt man algorithmische Kompression. Algorithmische Kompression ist genau das, womit sich die Naturwissenschaften und insbesondere auch die Informatik beschäftigt. Ein interessanter subtiler und leicht zu übersehender Aspekt der algoritmischen Kompression ist die Tatsache, dass die gefundenen Algorithmen die Anfangsbedingung enthalten. Die obige Formel gibt also keinen Aufschluss darüber, warum die 5 am Anfang der Zahlenreihe steht. Die Wahl einer anderen Anfangsbedingung z.B. die 2 ergibt eine völlig andere Zahlenreihe. Demzufolge werden mit einer anderen Anfangsbedingung auch andere Ereignisse vorhersagbar oder nachvollziehbar. Dies ist aber nicht die einzige Schwierigkeit der algorithmischen Kompression. Es gibt Ereignisfolgen, die sich nicht algorithmisch komprimieren lassen. Ein weiteres einfaches Beispiel aus der Mathematik soll das verdeutlichen. Die Zahlenreihe 
besteht, wie man schnell erkennen kann, aus Primzahlen, also Zahlen die nur durch sich selbst oder durch 1 geteilt werden können. Für eine derartige Zahlenreihe gibt es keine algorithmische Kompression. Jedes einzelne Ereignis muss einzeln hingeschrieben werden und auch ein Computer könnte nur durch testen der Primzahlbedingung herausfinden, ob eine Zahl eine Primzahl ist oder nicht. Es gibt also Ereignisse, die nicht voneinander ableitbar sind. Es gibt auch einzelne Ereignisse, die sich durch keine algorithmische Kompression, sondern sich nur durch Aufschreiben des einzelnen Ereignisses selbst beschreiben lassen. Ein weiteres Beispiel aus der Mathematik ist die Zahl PI oder auch die Eulersche Zahl e. ZusammenfassungDie algoritmische Kompression ist das Handwerkszeug der Informatik.Die Algorithmische Kompression liefert Algorithmen, die die Anfangsbedingung enthalten. Nicht jede Ereignisfolge lässt sich algorithmisch komprimieren. Es gibt Einzelereignisse, die sich aus keinem vorangegangenen Ereignis ableiten lassen. Welche praktische Bedeutung hat diese Betrachtung ?Auf der einen Seite beschäftigt sich die Informatik mit der Analyse von Prozesssen und der darin verborgenen Algorithmen, um diese mit Hilfe von Programmiersprachen in Computern abzubilden. Auf der anderen Seite steht der Nutzer dieser Algorithmen und erwartet häufig genug auch, dass mit diesen Algorithmen die Richtigkeit der Anfangsbedingungen auch geklärt werden kann. Konkret erwartet der Nutzer auch die Möglichkeit die Richtigkeit seiner Unternehmensprozesse mit Hilfe der EDV beurteilen zu können, also Unternehmensentscheidungen auf Grund der Ergebnisse seiner EDV-Anwendung treffen zu können.Dass diese Hoffnung nicht erfüllt werden kann, beweist die vorangegangene Betrachtung. Die Richtigkeit eines Prozesses, der mittels Algorithmen beschrieben wird, ist damit abhängig von den gewählten Anfangsbedingungen, die durch die Algorithmen selbst nicht erklärt werden können. Zudem gibt es Ereignisse die selbst bei genauester Analyse nicht in den gefundenen Algorithmen enthalten sind. Diese müssen also einzeln ausprogrammiert werden. Dies ist ein weiterer Konflikt zwischen Entwickler und Nutzer. Vom Entwickler werden derartige Probleme meist nicht bewusst wahrgenommen. Dem Entwickler ist es verborgen, dass die Algorithmen für die Beschreibung bestimmter Prozesse gewisse Einzelereignisse nicht berechnen können, da diese ihm nie geschildert wurden. Der Nutzer hingegen erwartet selbstverständlich, dass die für einen bestimmten Bereich eingesetzten Programme auch alle in diesem Bereich auftretenden Ereignisse bearbeiten können. Und schliesslich gibt uns die obige Betrachtung einen Ausblick auf die Tauglichkeit von Standardprogrammen. Standardprogramme sind eine Zusammenstellung von Algorithmen, die wiederum die Anfangsbedingung enthalten. Dass diese Anfangsbedingungen für ein allgemeines Unternehmensmodell zutreffen werden, ist zu erwarten, ob diese aber auf ein bestimmtes Unternehmen zutreffen werden, ist eher in Frage zu stellen. Es ist unvermeidlich, dass man mit dieser Aussage den Unmut der Mitarbeiter von SAP, Baan, Navision und den vielen anderen Standardprogrammherstellern wecken wird. Diese werden sofort entgegenhalten, dass man sich dem Umstand der mangelden Vollständigkeit und mangelden Anwendbarkeit eines Standardprogrammes auf alle Unternehmen durchaus bewusst sei. Als Abhilfe gäbe es aber die soggenannte Customization, also die vollständige Anpassbarkeit des Programmes an die Kundenwünsche. Die obige Betrachtung zeigt aber, dass sich hinter dem Wort Customization nicht anderes als eine teilweise Neuprogrammierung des Standardprogrammes versteckt. Die Informatik bietet nicht nur den rein funktionalen mathematischen Weg, sondern auf der anderen Seite auch die Möglichkeit Daten zu speichern. Zum besseren Verständnis ein Beispiel. Man denke sich einen Computer, in dem alle Ereignisse, die in sein Aufgabengebiet fallen, fest gespeichert sind und bei Auftreten eines entsprechenden Ereignisses abgerufen werden können. Man denke sich einen Computer in dem ein Datenpool abgelegt ist. Dieser Datenpool enthalte sämtliche Kundenadressen permutiert mit allen angebotetenen Artikeln in Form von Rechnungen. Kauft ein Kunde nun eine beliebige Wahl an Artikeln, muss nur die zu diesem Vorgang passende Rechnung herausgesucht und ausgedruckt werden. Dass dies keine praktikable Lösung ist, soll hier nicht untersucht werden. Es wird aber damit deutlich, dass die Informatik zwei Extrema besitzt. Zum einen die reine Logik und zum anderen die reine Speicherung von Daten. 
Man wird vermuten, dass irgendwo dazwischen das Optimum liegt und wird erwarten, dass man dieses nur kennenlernen muss, um alle zukünftigen Probleme zu meistern. Die Vermutung mag zutreffen, aber bisher wurde dieses Optimum noch nicht gefunden. In dieser Betrachtung ist es kaum erfolgreich sich nun mit der Geschichte der Informatik zu befassen und zu untersuchen, welche Methoden in den letzten 70 Jahren auf der Suche nach dem goldenen Mittelweg nun erfolgreich waren und welche verworfen wurden. Ein Begriff, der wie eine Schlagzeile im Geschichtsbuch der Informatik steht, sollte aber herausgriffen werden. Diese Schlagzeile besteht aus nur einem Wort. AbstraktionMit diesem Begriff ist die Methode gemeint, Probleme so nah wie möglich am Problem zu beschreiben und nicht ausgiebig Methoden zu beschreiben, mit denen das Problem schliesslich gelöst werden kann.Ein Bespiel soll dies verdeutlichen. Eine der Hauptaufgaben von Computern ist das Sortieren von Datensätzen. Tatsächlich wird der grösste Anteil an Rechenzeiten weltweit genau für diese Aufgabe verwendet. Als die Informatik noch in den Kinderschuhen steckte, war es notwenig, komplizierte von den technischen Voraussetzungen abhängige Verfahren zu programmieren, die eine schnelle und sinnvolle Sortierung von Daten ermöglichte. Die Probleme bestanden in mangelden Resourcen (geringer Arbeitsspeicher), komplizierte technische Speichermedien, wie externe Bandlaufwerke langsame Datenübertragungswege usw. Die Sortieralgorithmen wurden handverlesen und mehrfach neu erfunden. In heutigen Programmiersprachen ist diese Aufgabe so stark abstahiert, dass für praktisch beliebig viele Datensätze ein einziges Kommando genügt nämlich sinnigerweise ,,sort``. In den zurückliegenden Jahren der EDV-Entwicklung wurden tausende von Sprachen unterschiedlichster Ausprägung entwickelt, die alle dazu dienen sollten, perfekt bestimmte Probleme besser und einfacher zu beschreiben. Es gibt Sprachen, die sich besonders gut für mathmatische Probleme eignen und es gibt andere, die besonders gut für die Beschreibung verwaltungstechnischer Probleme geeignet sind und dritte, die sich vor allem mit grafischen Darstellungen beschäftigen und wieder andere, mit denen besonders gut Spiele programmiert werden können. Diese vielen sehr unterschiedlichen Sprachen sind als Werkzeuge zu verstehen, die besonders gut für bestimmte Klassen von Problemen geeignet sind. Man könnte an dieser Stelle eine Ausführung über Objekt-orientierte Programmierung erwarten, worauf aber verzichtet werden soll, da es sich um nicht viel anderes handelt, als eine weitere Methode der Abstraktion, die in jüngster Zeit besonders gefeiert wird. Im ersten Teil dieser Untersuchung wurden mehr Fragen aufgeworfen als Lösungen geboten. Dennoch ist die Welt voll mit Computern und es finden sich da und dort auch sehr brauchbare und sinnvolle Lösungen. Wie also sollte ein Weg in die Zukunft aussehen? Was wird Bestand haben, welche Methoden soll man anwenden? Bisher enthielten Programme, die typischerweise in PLI, Cobol oder Fortran geschrieben waren, sowohl die Manipulation als auch die Verwaltung der Daten vollständig. Damit entstand ein monolitischer Block, der bei fehlerhaftem Verhalten unglücklichen Einfluss auf das ganze System nehmen konnte. Diese Programme stellen noch einen wesentlichen Anteil aller auf der Welt eingesetzten Computerprogramme. Es war deshalb erforderlich zu untersuchen, welchen Aufwand die Erstellung und Wartung derartiger Programme bedeutet. Diese Programme sind üblicherwiese grosse monolitische Blöcke mit vielen 100000 Zeilen. Zunächst nahm man an, dass der zeitliche Aufwand für die Entwicklung derartiger Programme linear mit der Anzahl der zu programmierenden Zeilen ansteigt. Schnell zeigte sich, dass diese Annahme nicht realistisch ist und von weiteren Bedingungen abhängt. 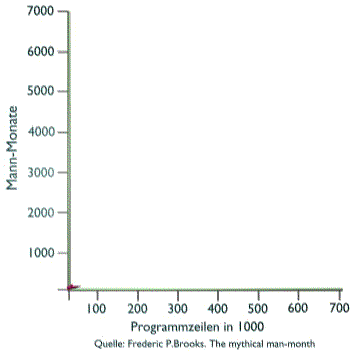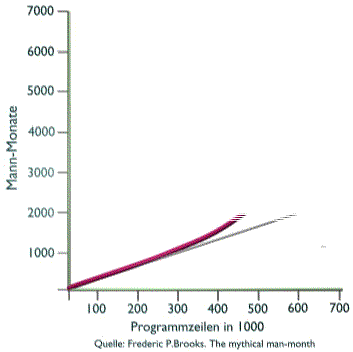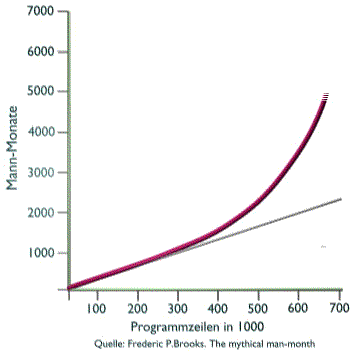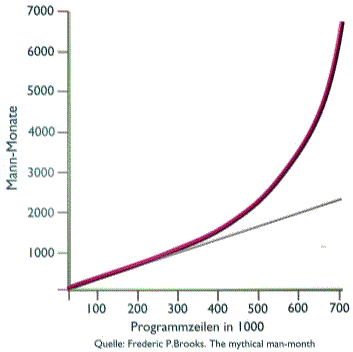
Neben vielen anderen Faktoren hängt es zum einen davon ab, wieviele Menschen an einem Programm arbeiten und zum anderen davon, wie stark die Notwendigkeit der Kommunikation zwischen diesen Menschen ist, um das gewünschte Ergebnis zu liefern. Es zeigt sich schnell, dass der zeitliche Aufwand unter Berücksichtigung dieser Faktoren schnell erheblich mit der Grösse des Programmes ansteigt. Im besonderen ist es auffällig aufwendig, ein bestehendes grosses Programm mit neuer Funktionalität zu erweitern. Zu einem Programm mit 600000 Zeilen 50000 Zeilen dazuzuschreiben dauert ein vielfaches länger als ein einzelnes Programm mit 50000 Zeilen neu zu entwicklen. Was bedeutet dies ?für die Erstellung von Individualsoftware? Eine typische Programmentwicklung beginnt mit einer Art Pflichtenheft, danach wird ein erster Prototyp entwickelt und zum Einsatz gebracht. Bei der Nutzung dieses Prototyps ergeben sich Probleme, Missverständnisse und Fehler werden aufgedeckt. Das Ergebnis wird folglich überarbeitet. Die neue Version kommt wieder zum Einsatz es zeigen sich weitere Wünsche es werden weitere Irrtümer aufgedeckt, es werden Mängel in der Funktionalität und im Umfang der Funktionalität erkannt. Die Version wird wieder verändert, erweitert. Bei der nächsten Inbetriebnahme fallen plötzlich schlummernde Fehler auf, die nun durch die Erweiterung und Veränderung zu Tage treten. Der Vorgang des änderns, das wieder neu Inbetriebnehmens wird aufwendiger und immer langwieriger, es entsteht Frust und Misstrauen bei den Nutzern und Ermüdung bei den Entwicklern. Doch selbst wenn der Prozess zu einer Erweiterung und Verbesserung führt, wächst das Volumen des Programmes ständig an und macht eine zusätzliche Erweiterung immer mühsamer und langfristiger, bis schliesslich praktisch keine Erweiterung in sinnvoller Zeit mehr erreichbar ist. Das Projekt steckt fest.Dies ist bei vielen grossen Systemen bei Banken, Versicherungen im Handel und in der Industrie schon so abgelaufen. Gibt es einen Ausweg ?Dass es einen Ausweg geben muss, ist zu erwarten, denn nichts ahndet die Wirtschaft so sehr wie Stillstand und so lastete auf der Informatik ein hoher evolutionärer Druck. Die Antwort, die heute durch die Informatik gegeben wird heisstEncapsulation
Um einen zentralen Datenpool scharen sich verschiedenste unabhängige Anwendungen, die durch die gemeinsamen Daten zu einem Stück werden. Die Erweiterung kann ohne Einfluss auf alle anderen Anwendungen geschehen. Die Optimierung einzelner Anwendung kann unabhängig von allen anderen durchgeführt werden. Schliesslich kann der Datenpool selbst, unter Einhaltung bestimmter Spielregeln, für neue Anwendungen erweitert werden, ohne dass bestehende Anwedungen berührt werden. Anwendungen können sogar wegfallen und durch andere ersetzt werden. Warum funktioniert so etwas?Zunächst einmal steht im Mittelpunkt die erfolgreiche Entwicklung der relationalen Datenbanken.Es gab zunächst den einfachen Ansatz der Datenspeicherung. Jedes Ereignis wurde einzeln gespeichert. Jede Änderung eines Artikels z.B. führte zu einem neuen Datensatz. Jede änderung einer Adresse ebenfalls usw.. Das Modell erinnert an das oben beschriebene Extrem der vollständigen Speicherung mit dem Unterschied, dass nicht sämtliche Möglichkeiten bereits vorgegeben sind, sondern im Laufe der Zeit hinzugefügt werden. Später verstand man, dass diese Speicherung von Daten eine hohe Redundanz bedeutete und wenig Aussagekraft besass. Man entwickelte ein neues, sehr erfolgreiches Modell der Datenspeicherung und bewegte sich so auf der gedachten Linie zwischen reiner Speicherung und reiner Logic ein wenig in Richtung Logik. Dieses Modell nannten die Informatiker 3. Normalform. Der entscheidende Durchbruch, den die dritte Normalform brachte war, zweifach!
Damit war ein enorm leistungsfähiges Werkzeug geboren, Daten strukturiert und dicht zu speichern und gleichzeitig in mathematisch logischer Form beliebig abzurufen. Gleichzeitig war erstmals der Weg frei, Datenstrukturen von Anwendungen zu trennen. Der Siegeszug der Datenbanken ist daher nicht unbegründet. Denn erstmals -- bereits vor der Erfindung der objektorientierten Programmierung -- hatte man bereits einen Weg gefunden, die Methode des Datenaufsuchens und Zusammenstellens so stark zu vereinfachen, dass Anwendungen erheblich kleiner und von der Datenstruktur unabhängiger werden konnten. Programmierer konten nun erstmals Datenbanken nutzen ohne die genaue Methode des Zusammenstellens, der Speicherung, des Sortierens und Lesens, verstehen zu müssen. Die Schnittstelle war eine abstrakte Sprache. Weitere technische Details sollen nicht Gegenstand dieser Betrachtung sein. Abschliessend eine Zusammenfassung der wesentlichen Aspekte der gemachten Ausführungen.
|

P
R
O
J
E
K
T
E